

先做个广告:如需代注册帐号或代充值Chatgpt Plus会员,请添加站长客服微信:pingzi7749
GPT-4o 的视频功能
API 发行说明中有关视频使用的重要说明:“API 中的 GPT-4o 支持通过视觉功能理解视频(不带音频)。具体来说,视频需要转换为帧(每秒 2-4 帧,统一采样或通过关键帧选择算法采样)才能输入到模型中。”使用OpenAI 视觉手册可以更好地了解如何使用视频作为输入以及版本的局限性。
GPT-4o 被证明既具有查看和理解上传的视频文件中的视频和音频的能力,也具有生成短视频的能力。
在初始演示中,GPT-4o 多次被要求对视觉元素进行评论或回应。与我们对Gemini 的初步观察类似,演示并未明确说明模型是在接收视频还是在需要“查看”实时信息时触发图像捕获。在初始演示中,有一段时间GPT-4o 可能没有触发图像捕获,因此看到了之前捕获的图像。
在 YouTube 上的这段演示视频中,GPT-4o “注意到” 一个人走到 Greg Brockman 身后,做了兔子耳朵。在可见的手机屏幕上,除了音效外,还会出现“眨眼”动画。这意味着 GPT-4o 可能使用与 Gemini 类似的视频处理方法,即在提取视频图像帧的同时处理音频。
 演示视频的裁剪部分展示了 GPT-4o“闪烁”的动画。
演示视频的裁剪部分展示了 GPT-4o“闪烁”的动画。
唯一演示的视频生成示例是 3D 模型视频重建,但据推测它可能具有生成更复杂视频的能力。
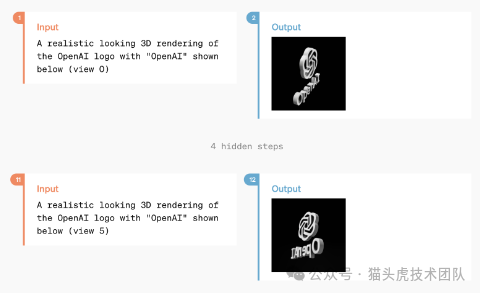
GPT-4o 之间的一次交换,用户请求并接收基于多张参考图像的旋转徽标的 3D 视频重建
GPT-4o 的音频功能
与视频和图像类似,GPT-4o 还具备提取和生成音频文件的能力。
GPT-4o 对生成的声音表现出了令人印象深刻的精细控制水平,能够改变交流速度、根据要求改变音调,甚至按需唱歌。GPT-4o 不仅可以控制自己的输出,还能理解输入音频的声音作为任何请求的附加上下文。演示显示,GPT-4o 会向试图说中文的人提供音调反馈,并在呼吸练习期间反馈某人的呼吸速度。
根据自行发布的基准测试,GPT-4o 的表现优于 OpenAI 自己的 Whisper-v3(自动语音识别(ASR)领域之前最先进的技术),并且优于 Meta 和 Google 的其他模型的音频翻译。
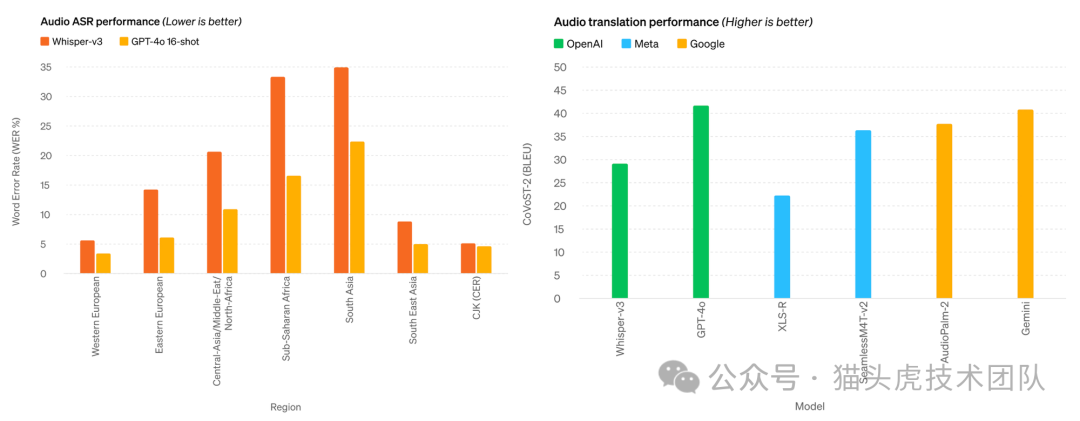
图片来源:OpenAI

本文链接:https://qh-news.com/chatgpt/66.html
chatgpt4官网下载地址chatgpt官网地址是多少chatgpt机器人官网中文版手机无法登录chatgpt官网chatgpt官网在哪里chatgpt官网永久免费免登录哪里能用chatgpt写文案官网chatgpt怎么进官网怎么才能访问chatgpt的官网chatgpt官网api密钥







