

先做个广告:如需代注册帐号或代充值Chatgpt Plus会员,请添加站长客服微信:pingzi7749
用 GPT-4 发现 GPT-4 的错误
CriticGPT 是一个基于 GPT-4 的模型,它对 ChatGPT 的回答进行批评,以帮助人类训练员在 RLHF 过程中发现错误。
我们训练了一个基于 GPT-4 的模型,名为 CriticGPT,用于捕捉 ChatGPT 代码输出中的错误。我们发现,当人们在审查 ChatGPT 代码时得到 CriticGPT 的帮助,他们 60% 的时间表现优于没有帮助的人。我们正在着手将类似 CriticGPT 的模型整合到我们的 RLHF 标注流程中,为我们的训练员提供明确的 AI 辅助。这是朝着能够评估高级 AI 系统输出的一步,这些输出如果没有更好的工具,人们可能难以评分。
GPT-4 系列模型(为 ChatGPT 提供动力)通过"人类反馈强化学习"(RLHF)来实现有帮助和互动的目标。RLHF 的一个关键部分是收集比较,其中被称为 AI 训练员的人员对不同的 ChatGPT 回答进行相互评分。
随着我们在推理和模型行为方面取得进展,ChatGPT 变得更加准确,而它的错误也变得更加微妙。这可能使 AI 训练员难以发现确实发生的不准确之处,使为 RLHF 提供动力的比较任务变得更加困难。这是 RLHF 的一个根本限制,随着模型逐渐变得比任何可以提供反馈的人更有知识,它可能会使模型的对齐变得越来越困难。
为了应对这一挑战,我们训练了 CriticGPT 来撰写批评,突出 ChatGPT 答案中的不准确之处。

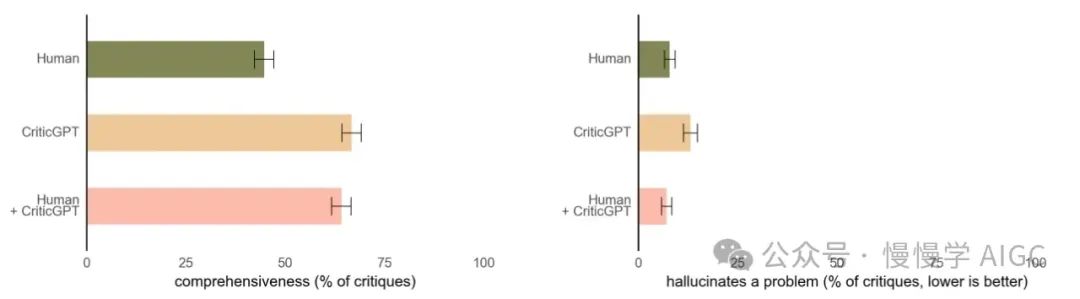
CriticGPT 的建议并不总是正确的,但我们发现它们可以帮助训练员捕捉到比没有 AI 帮助时更多的模型书写答案中的问题。此外,当人们使用 CriticGPT 时,AI 增强了他们的技能,产生的批评比人们单独工作时更全面,比模型单独工作时产生的幻觉错误更少。在我们的实验中,第二个随机训练员超过 60% 的时间更倾向于人类+CriticGPT 团队的批评,而不是未经辅助的人的批评。
方法
CriticGPT 也是通过 RLHF 训练的,类似于 ChatGPT。但与 ChatGPT 不同的是,它看到了大量包含错误的输入,然后必须对这些错误进行批评。我们要求 AI 训练员手动将这些错误插入到 ChatGPT 编写的代码中,然后写出示例反馈,就好像他们刚刚发现了他们插入的错误。然后,同一个人比较了对修改后代码的多个批评,这样他们就可以轻松地判断出哪个批评捕捉到了他们插入的错误。在我们的实验中,我们既研究了 CriticGPT 是否能捕捉到插入的错误,也研究了先前训练员捕捉到的 ChatGPT"自然发生"的错误。我们发现,在自然发生的错误上,训练员在 63% 的情况下更喜欢 CriticGPT 的批评而不是 ChatGPT 的批评,部分原因是新的批评者产生的"吹毛求疵"(不太有帮助的小抱怨)更少,幻觉出问题的频率也更低。
我们还发现,通过对批评奖励模型使用额外的测试时搜索,我们可以生成更长、更全面的批评。这种搜索程序允许我们平衡我们在代码中寻找问题的积极程度,并在幻觉和检测到的错误数量之间配置精确度-召回率权衡。这意味着我们可以生成对 RLHF 尽可能有帮助的批评。更多细节请参见我们的研究论文。
局限性
我们在非常短的 ChatGPT 答案上训练了 CriticGPT。为了监督未来的代理,我们需要开发能够帮助训练员理解长期和复杂任务的方法。
模型仍然会产生幻觉,有时训练员在看到这些幻觉后会做出错误的标注。
有时,现实世界中的错误可能分散在答案的多个部分。我们的工作侧重于可以在一个地方指出的错误,但在未来我们需要解决分散的错误。
CriticGPT 的帮助是有限的:如果一个任务或回答极其复杂,即使是一个有模型帮助的专家也可能无法正确评估它。
下一步
为了对齐日益复杂的 AI 系统,我们需要更好的工具。在我们对 CriticGPT 的研究中,我们发现将 RLHF 应用于 GPT-4 有望帮助人类为 GPT-4 产生更好的 RLHF 数据。我们计划进一步扩大这项工作的规模并将其付诸实践。

本文链接:https://qh-news.com/chatgpt/47.html
手机无法登录chatgpt官网chatgpt怎样登录官网chatgpt4.0 官网地址chatgpt官网桌面版使用教程chatgpt官网登录不了chatgpt官网在线使用国内怎么登陆chatgpt官网进口chatgpt短视频角本生成官网哪里能用chatgpt写文案官网怎么才能访问chatgpt的官网







