先做个广告:如需代注册帐号或代充值Chatgpt Plus会员,请添加站长客服微信:pingzi7749
1.什么是 GPT-4o
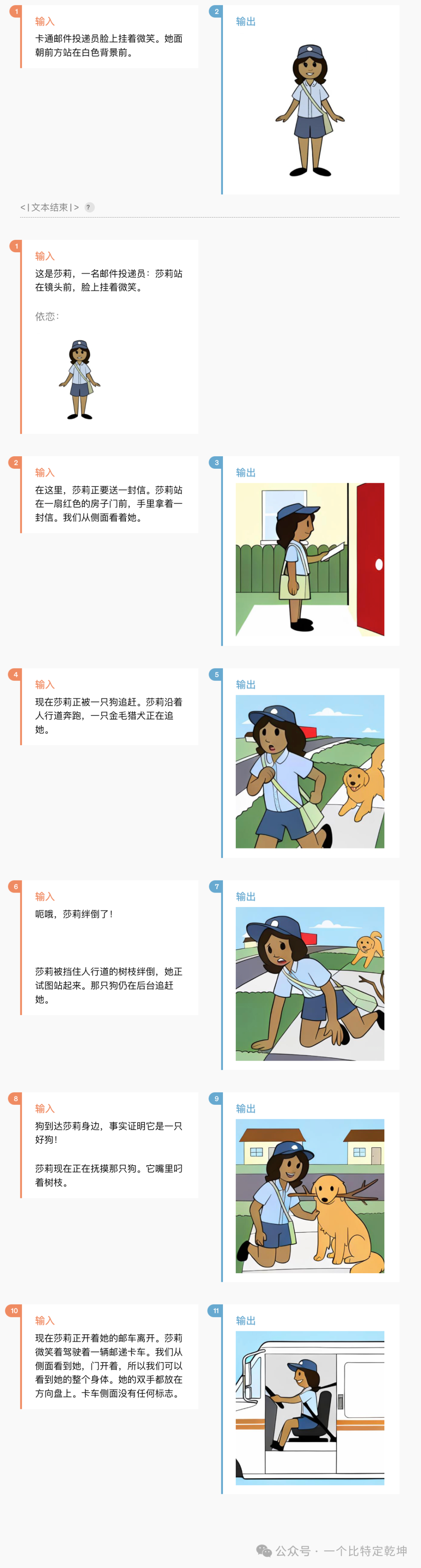
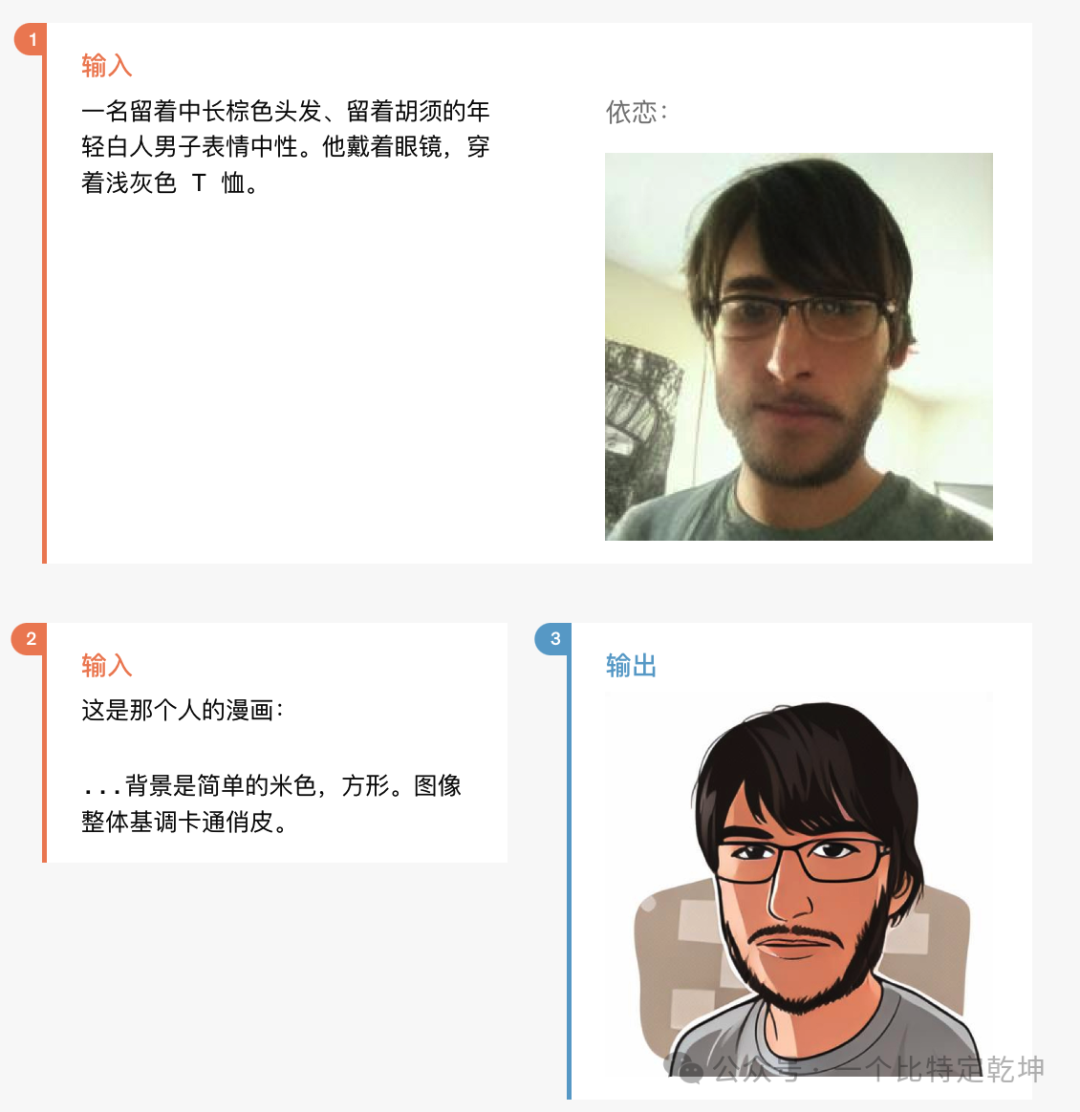
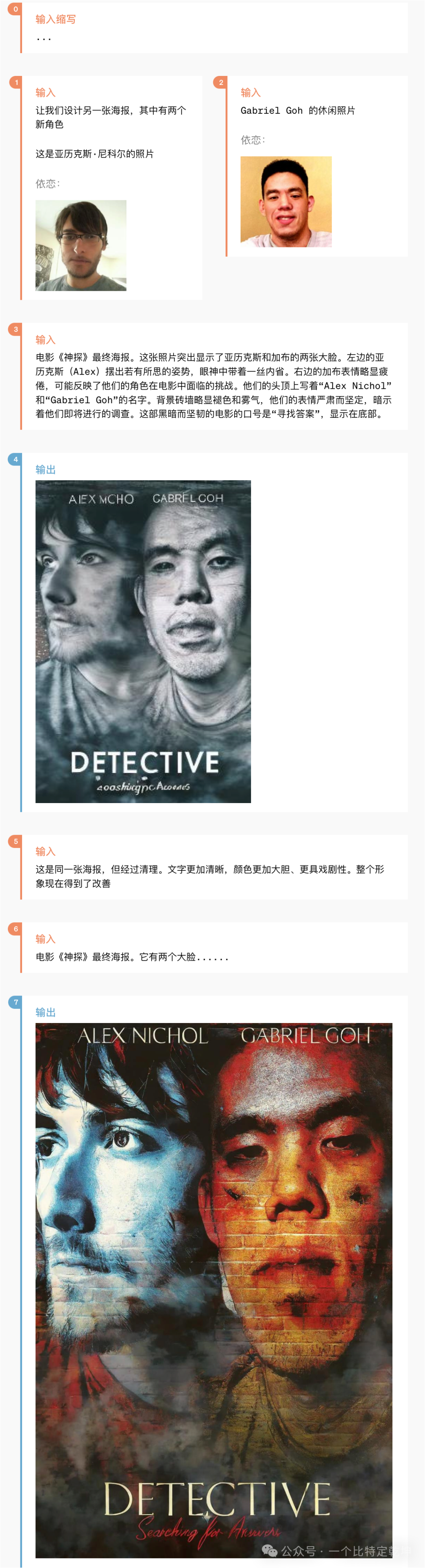
当地时间 2024年5月13日 OpenAI 发布了 GPT-4o。GPT-4o("o"代表"omni",全部、整体的意思)是 OpenAI 新的旗舰模型,可以实时推理音频、视觉和文本,是迈向更自然的人机交互的一步。
它接受文本、音频、图像和视频的任意组合作为输入,并生成文本、音频和图像的任意组合输出。它可以在短至 232 毫秒的时间内响应音频输入,平均为 320 毫秒,与人类的响应时间相似。它在英语文本和代码上的性能与 GPT-4 Turbo 的性能相匹配,在非英语文本上的性能显着提高,同时 API 的速度也更快,成本降低了 50%。与现有模型相比,GPT-4o 在视觉和音频理解方面尤其出色。在 GPT-4o 之前,可以使用语音模式与 ChatGPT 对话,平均延迟为 2.8 秒 (GPT-3.5) 和 5.4 秒 (GPT-4)。语音模式是由三个独立模型组成的管道:(2)使用 GPT-3.5 或 GPT-4 接收文本并输出文本这个过程意味着主要智能来源GPT-4丢失了大量信息——它无法直接观察音调、多个说话者或背景噪音,也无法输出笑声、歌唱或表达情感。
借助 GPT-4o,在跨文本、视觉和音频端到端地训练了一个新模型,这意味着所有输入和输出都由同一神经网络处理。GPT-4o 是第一个结合所有这些模式的模型,同时也正在探索该模型的功能及其局限性。先看一段 GPT-4o 识别视频场景、语音交互、自然对话的视频(听力太差、翻译可能有误,敬请谅解):「视频来自 https://openai.com/index/hello-gpt-4o 」视频中,GPT-4o 展示了更短的输出时延、更自然的对话(语音语调更像人类)、以及更精确视频场景识别等能力。有关GPT1-GPT4的模型详解请看:
官网展示了许多关于多模态的能力,我这里总结一些,如下:![]()
![]()
![]() 2.6 多模态输出根据传统基准测试,GPT-4o 在文本、推理和编码智能方面实现了 GPT-4 Turbo 级别的性能,同时在多语言、音频和视觉功能上设置了新的高水位线。
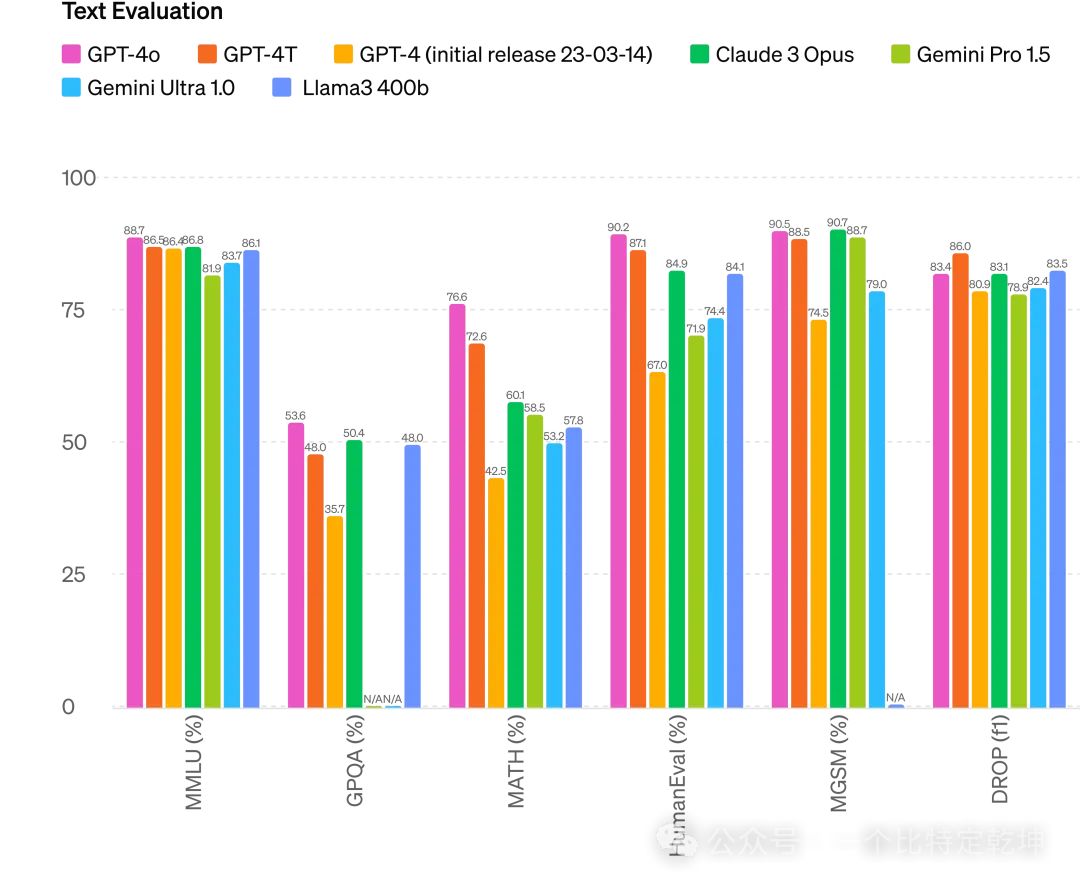
2.6 多模态输出根据传统基准测试,GPT-4o 在文本、推理和编码智能方面实现了 GPT-4 Turbo 级别的性能,同时在多语言、音频和视觉功能上设置了新的高水位线。![]() 改进推理: GPT-4o 在 0-shot COT MMLU(常识问题)上创下了 88.7% 的新高分。此外,在传统的 5-shot no-CoT MMLU上,GPT-4o 创下了87.2%的新高分。
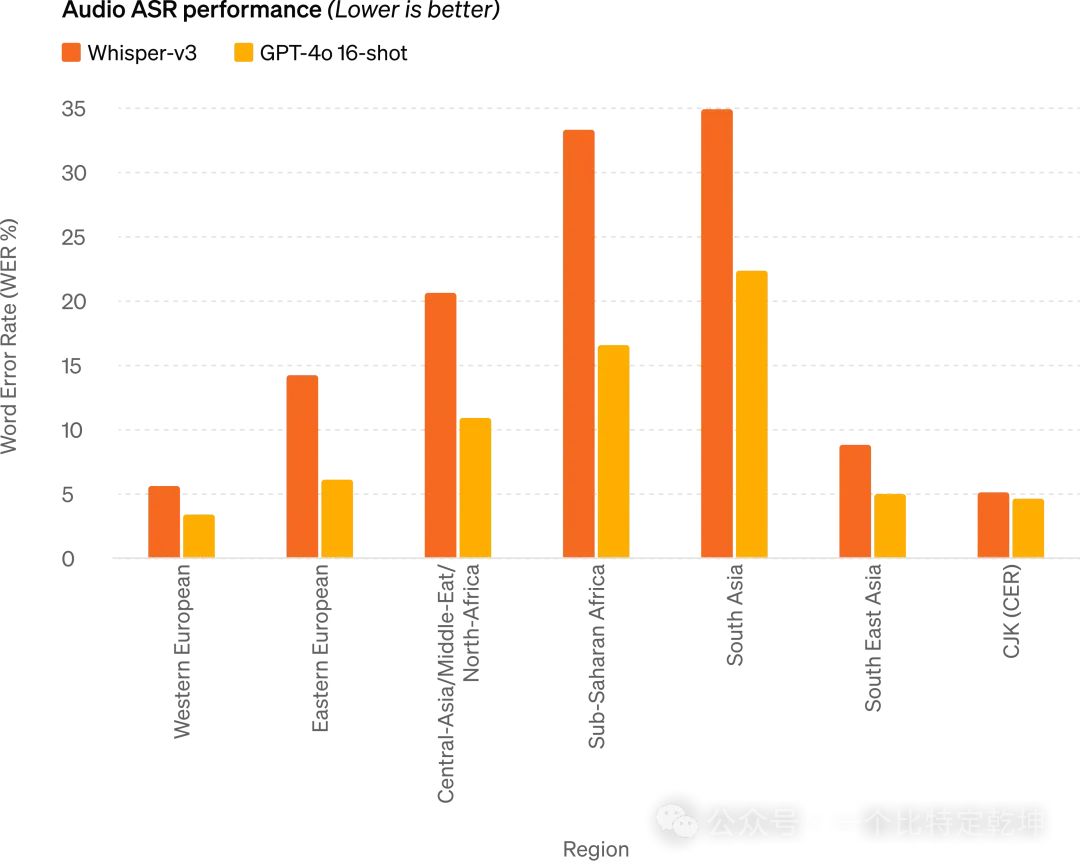
改进推理: GPT-4o 在 0-shot COT MMLU(常识问题)上创下了 88.7% 的新高分。此外,在传统的 5-shot no-CoT MMLU上,GPT-4o 创下了87.2%的新高分。![]() 音频 ASR 性能: GPT-4o 比 Whisper-v3 显着提高了所有语言的语音识别性能(特别是对于数据匮乏的语言)
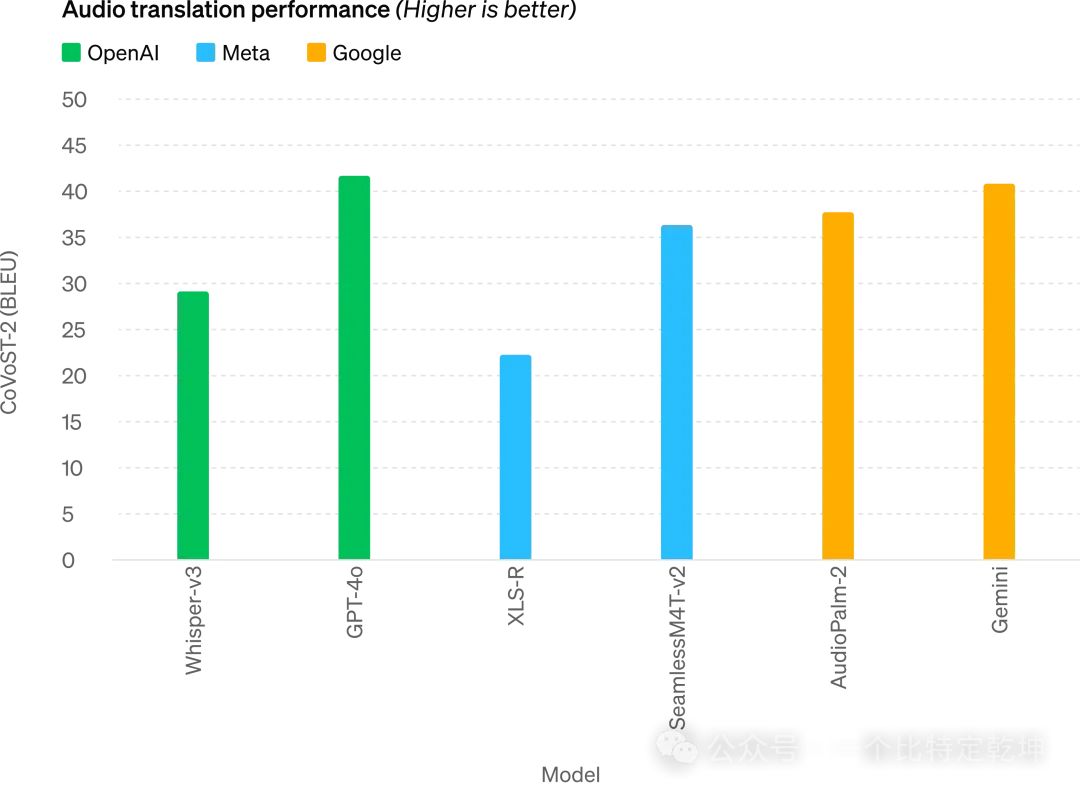
音频 ASR 性能: GPT-4o 比 Whisper-v3 显着提高了所有语言的语音识别性能(特别是对于数据匮乏的语言)![]() 音频翻译性能: GPT-4o 在语音翻译方面创造了新的最先进水平,并且在 MLS 基准测试中优于 Whisper-v3。3.4 M3Exam 零样本(Zero-Shot)结果
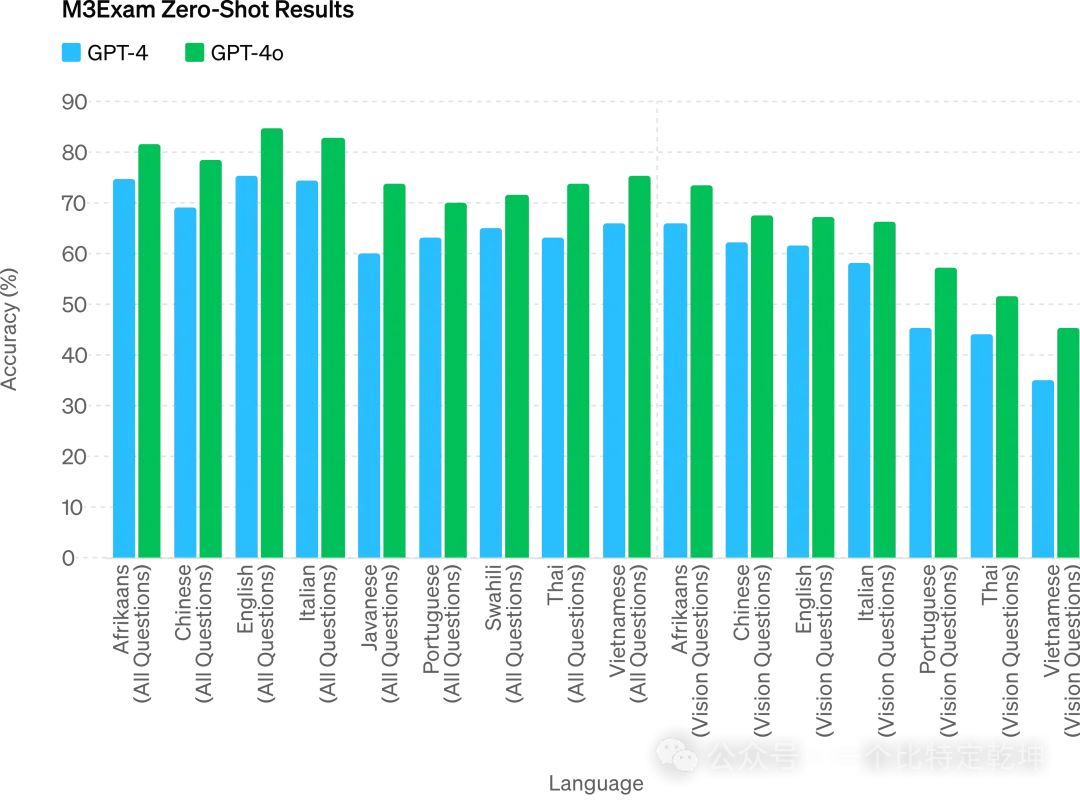
音频翻译性能: GPT-4o 在语音翻译方面创造了新的最先进水平,并且在 MLS 基准测试中优于 Whisper-v3。3.4 M3Exam 零样本(Zero-Shot)结果![]() M3Exam: M3Exam 基准是多语言和视觉评估,由来自其他国家标准化测试的多项选择题组成,有时包括图形和图表。在所有语言的基准测试中,GPT-4o 都比 GPT-4 更强。(省略了斯瓦希里语和爪哇语的视力结果,因为这些语言的视力问题只有 5 个或更少。)
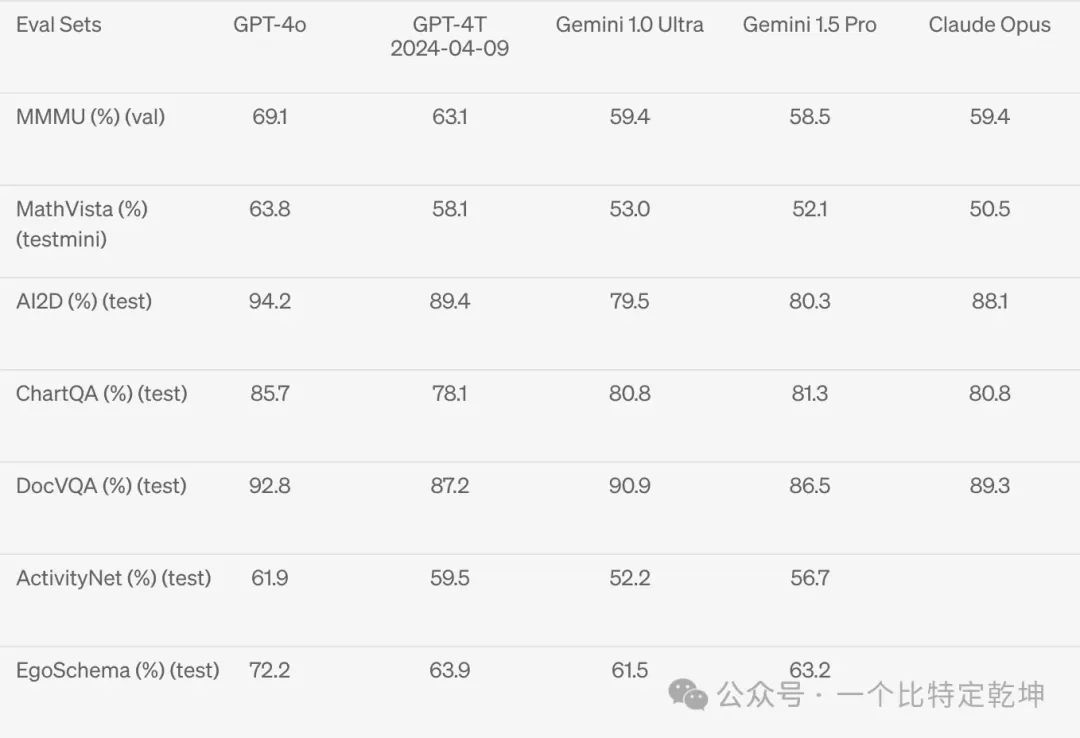
M3Exam: M3Exam 基准是多语言和视觉评估,由来自其他国家标准化测试的多项选择题组成,有时包括图形和图表。在所有语言的基准测试中,GPT-4o 都比 GPT-4 更强。(省略了斯瓦希里语和爪哇语的视力结果,因为这些语言的视力问题只有 5 个或更少。)3.5 视觉理解评估![]()
视觉理解评估: GPT-4o 在视觉感知基准上实现了最先进的性能。所有视觉评估都是 0-shot,其中 MMMU、MathVista 和 ChartQA 作为 0-shot CoT。GPT-4o 是 OpenAI 新推出的旗舰模型,可以实时推理音频、视觉和文本,具有独特的优势:增强的上下文感知: GPT-4o 擅长在较长的对话中保持上下文。它可以记住聊天早期的详细信息,并使用该信息提供更准确和相关的响应。这让您感觉更像是在与一个记得对话流程的真人交谈。GPT-4o 生成的响应更流畅、更连贯,使交互感觉更自然,这对于保持自然对话流程很重要的应用程序(例如客户支持或虚拟助理)特别有用。强大的多模态能力: GPT-4o 跨文本、视觉和音频端到端地训练了一个新模型,接受文本、音频、图像和视频的任意组合作为输入,并生成文本、音频和图像的任意组合输出,能实现更加强大的多模态能力。优异的模型性能:借助统一的多模态模型,在文本理解、音频性能、音频翻译、视觉理解等多领域都达到领先水平,具备优异的模型性能。https://openai.com/index/hello-gpt-4o欢迎关注本人,我是喜欢搞事的程序猿;一起进步,一起学习;也欢迎关注我的wx公众号(精选高质量文章):一个比特定乾坤

本文链接:https://qh-news.com/chatgpt/35.html
chatgpt4.0手机版官网chatgpt官网地址是多少正规chatgpt写文案官网chatgpt官网地址是什么手机chatgpt官网入口chatgpt官网怎么注册不了chatgpt插件官网chatgpt官网现在要排队吗chatgpt官网什么样子chatgpt官网如何下载






 2.6 多模态输出
2.6 多模态输出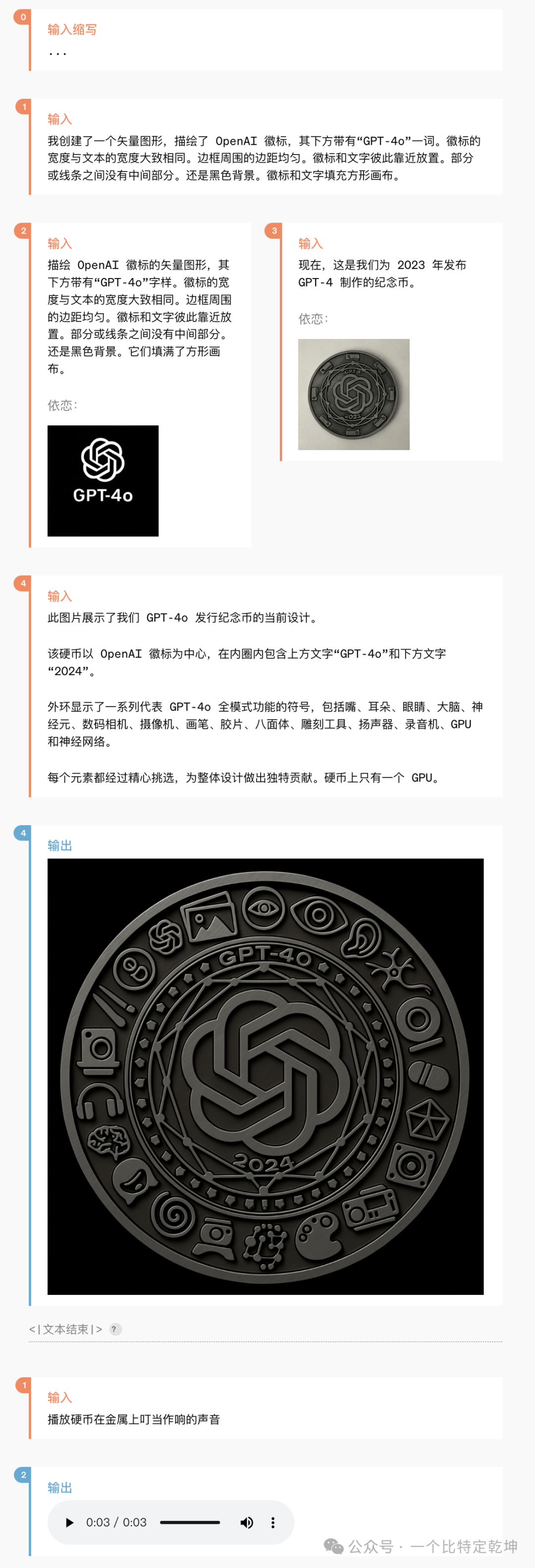
 改进推理: GPT-4o 在 0-shot COT MMLU(常识问题)上创下了 88.7% 的新高分。此外,在传统的 5-shot no-CoT MMLU上,GPT-4o 创下了87.2%的新高分。
改进推理: GPT-4o 在 0-shot COT MMLU(常识问题)上创下了 88.7% 的新高分。此外,在传统的 5-shot no-CoT MMLU上,GPT-4o 创下了87.2%的新高分。