

先做个广告:如需代注册帐号或代充值Chatgpt Plus会员,请添加站长客服微信:pingzi7749
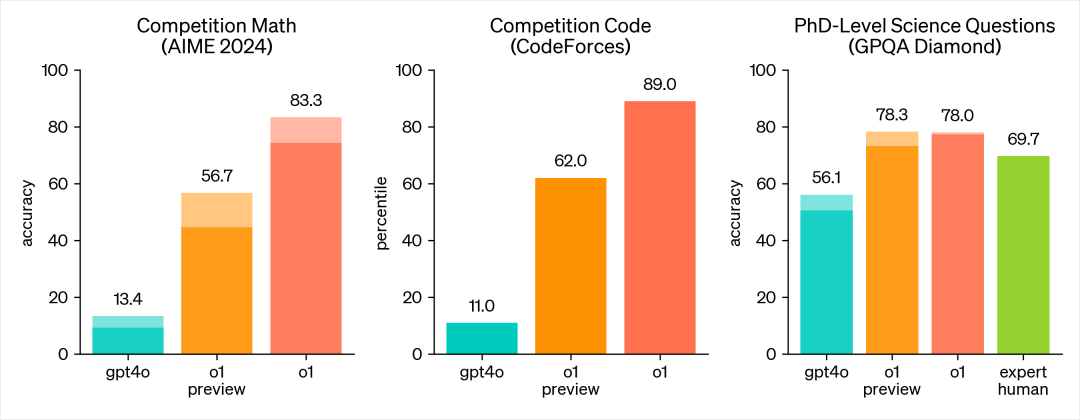
以CodeForces为测试题,GPT-4o 准确率为11%,o1 preview版本的正确率为62%,o1正式版的正确率为89%;
最后,以GPQA Diamond为测试题,GPT-4o 准确率为56.1%,o1 preview版本的正确率为78.3%,o1正式版的正确率为78%,后面是人类专家的正确率69.7%。
这次发布的o1有三个不同的版本,分别是o1、o1 preview以及o1 mini。上面测试的数据中没有o1 mini。现阶段除了o1外,另外两种模型已经开放给plus跟team会员使用,未来会考虑开放给所有免费用户。
以下是三种模型的介绍:
o1-新的大模型天花板,由于性能过于强大,还不方便对外公布;
o1 preview-o1的早期版本,现已开放给plus与team会员使用;
o1 mini-速度更快、性价比更高,适用于需要推理和无需广泛世界知识的任务;
如果看不懂o1 mini与preview,可以回看这篇草莓模型,看完你就会知道什么叫无需广泛世界知识任务。
针对o1模型,OpenAI员工一般都是【系统1】和【系统2】来区分o1与之前的模型。
o1通过Self play RL来学会思维链,并从中知道如何识别和纠正错误。以OpenAI这种用户的量级,o1每天进步的速度是很恐怖的。
我想象不到明年的这个时候,o1会有多强。
现阶段,普通用户的访问次数是:o1 preview是每周30条,o1 mini是每周50条。
开发者的访问次数是:每分钟20条,但仅对于等级5或以上开放(支付过超过1000美金)。
以周为计算单位,与之前3小时80条简直是天壤之别!!!
未来,应该会开设不同的订阅级别,以满足不同人群的访问需求。200美元只是起步,上不封顶可能没有,但2000美元应该不是空谈。
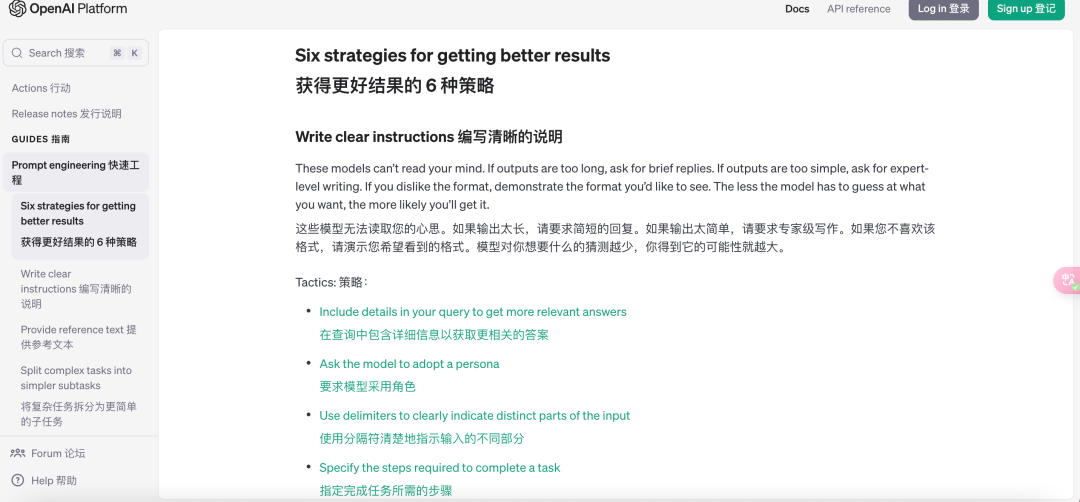
至于提示词书写格式,OpenAI给了个格式:
1.编写清晰的说明
2.提供参考文本
3.将复杂任务拆分成更简单的子任务
4.给模型时间“思考”
5.使用外部工具
6.系统地测试与优化更改
听起来有点拗口,所以我稍微简化了一下:
保持提示简单直接:模型擅长理解和响应简短、清晰的指令,不需要大量指导;
避免思路链提示:o1本身就采用了Self play RL,所以不需要再提示它们“逐步思考”或“解释你的推理”。比如过去我们常常用【请一步一步思考】等这样的提示词去让GPT更有条理地思考,从而输出更贴合我们需求的回答;
使用分隔符来提高清晰度:使用三重引号、XML 标签等分隔符来清楚地指示输入的不同部分,帮助模型适当地解释不同的部分。这部分还是跟之前的提示词格式一样;
限制检索增强生成 (RAG) 中的附加上下文:提供上下文或文档时,只包含最相关的信息,防止o1模型过度复杂化。
〔写在最后〕

本文链接:https://qh-news.com/chatgpt/104.html
可以用的chatgpt官网chatgpt官网汉化怎样进chatgpt官网chatgpt官网中文版手机版如何登录chatgpt官网chatgpt官网打不开了吗时代飞鹰chatgpt官网chatgpt官网百度chatgpt官网如何转换中文chatgpt怎么进官网







